

Photo by Erik Mclean on Unsplash
12 Ways of Getting Ready for Microservices
Paving the way to microservices


Your team decided it’s time to get rid of that old, clunky monolith (finally!). You had a good run with it, but the monolith has grown so big that you're spending more effort maintaining it than adding features. It's time to try a different approach.
It seems microservices are very popular these days, so maybe it makes sense to dig a bit deeper there and see what all the fuss is about?
A word of advice: don’t write off the monolith just yet. With some preparation, it can serve you well all the way through the transition. Here are 12 tips for making the transition to microservices smooth as possible.
Ensure you know what you’re getting into
A rewrite is never an easy journey, but by moving from monolith to microservices, you are changing more than the way you code; you are changing the company's operating model. Not only do you have to learn a new, more complex tech stack but management will also need to adjust the work culture and reorganize people into smaller, cross-functional teams.
How to best reorganize the teams and the company are subjects worthy of a separate post. In this article, I want to focus on the technical aspects of the migration.
First, it’s important to research as much as possible about the tradeoffs involved in adopting microservices before even getting started. You want to be absolutely sure that microservices (and not other alternative solutions such as modularized monoliths) are the right solution for you.
Start by learning everything you can about the microservice architecture, and check some example projects to get an idea of how it works. Here are some examples:
Make a plan
It takes a lot of preparation to tear down a monolith since the old system must remain operational while the transition is made.
The migration steps can be tracked with tickets and worked towards in each sprint like any other task. This not only helps in gaining momentum (to actually someday achieve the migration), but gives transparency to the business owners regarding how the team is planning on implementing such a large change.
During planning, you have to:
- Disentangle dependencies within the monolith.
- Identify the microservices needed.
- Design data models for the microservices.
- Develop a method to migrate and sync data between monolith and microservices databases.
- Design APIs and plan for backward compatibility.
- Capture the baseline performance of the monolith.
- Set up goals for the availability and performance of the new system.
Unless you’re migrating from a fairly simple monolith, you’ll need advanced techniques, such as Domain-Driven Design (DDD), by your side. If you’ve never used it before, I’ve written a short introduction on applying DDD to microservices that’s worth a read.
Put everything in a monorepo
As you break apart the monolith, a lot of code will be moved away from it and into new microservices. A monorepo helps you keep track of these kinds of changes. In addition, having everything in one place can help you recover from failures more quickly.
In all likelihood, your monolith is already contained in one repository. So, it’s just a matter of creating new folders for the microservices.
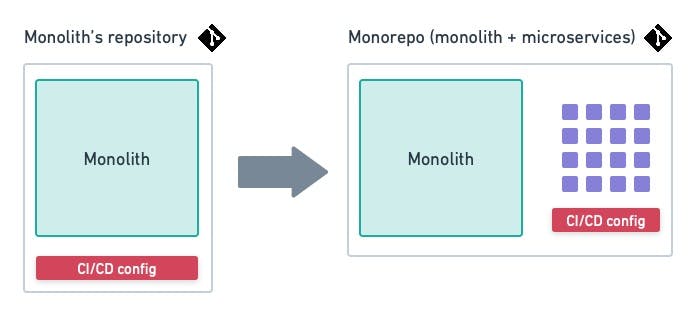
Caption: a monorepo is a shared repository containing the monolith and the new microservices.
Use a shared CI pipeline
During development, you’ll not only be constantly shipping out new microservices but also re-deploying the monolith. The faster and more painless this process is, the more rapidly you can progress. Set up continuous integration and delivery (CI/CD) to test and deploy code automatically.
If you are using a monorepo for development, you’ll have to keep a few things in mind:
- Keep pipelines fast by enabling change-based execution or using a monorepo-aware build tool such as Bazel or Pants. This will make your pipeline more efficient by only running changes on the updated code.
- Configure multiple promotions, one for each microservice and one more for the monolith. Use these promotions for continuous deployment.
Configure test reports to quickly spot and troubleshoot failures.
Ensure you have enough testing
Refactoring is much more satisfying and effective when we are sure that the code has no regressions. Automated tests give the confidence to continuously ship out monolith updates.
An excellent place to start is the testing pyramid. You will need a good amount of unit tests, some integration tests, and a few acceptance tests.
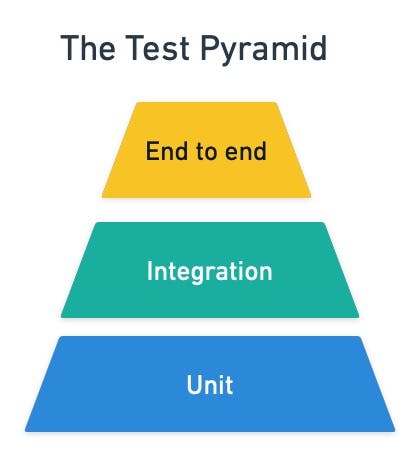
Caption: the testing pyramid
Aim to run the tests as often on your local development machine as you do in your continuous integration pipeline.
Install an API Gateway or HTTP Reverse Proxy
As microservices are deployed, you have to segregate incoming traffic. Migrated features are provided by the new services, while the not-yet-ready functionality is served by the monolith.
There are a couple of ways of routing requests, depending on their nature:
- An API gateway lets you forward API calls based on conditions such as authenticated users, cookies, feature flags, or URI patterns.
- An HTTP reverse proxy does the same but for HTTP requests. In most cases, the monolith implements the UI, so most traffic will go there, at least at first.
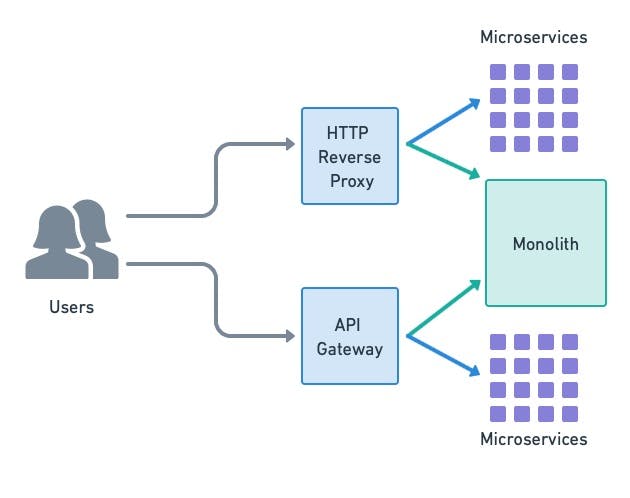
Caption: use API gateways and HTTP reverse proxies to route requests to the appropriate endpoint. You can toggle between the monolith and microservices on a very fine-grained level.
Once the migration is complete, the gateways and proxies will remain – they are a standard component of any microservice application since they offer forwarding and load balancing. They can also function as circuit breakers if a service goes down.
The monolith-in-a-box pattern
OK, this one only applies if you plan to use containers or Kubernetes for the microservices. In that case, containerization can help you homogenize your infrastructure. The monolith-in-a-box pattern consists of running the monolith inside a container such as Docker.
If you've never worked with containers before, this is a good opportunity to get familiar with the tech. That way, you'll be one step closer to learning about Kubernetes down the road. It's a lot to learn, so plan for a steep learning curve:
- Learn about Docker and containers.
- Run your monolith in a container.
- Develop and run your microservices in a container.
- Once the migration is done and you've mastered containers, learn about Kubernetes.
- As the work progresses, you can scale up the microservices and gradually move traffic to them.
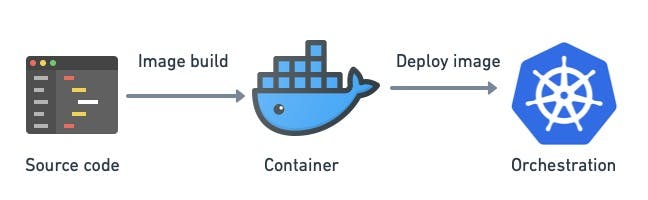
Caption: containerizing your monolith is a way of standardizing deployment, and it is an excellent first step in learning Kubernetes.
Warm up to changes
It takes time to get used to microservices, so it’s best to start small and warm up to the new paradigm. Leave enough time for everyone to get in the proper mindset, upskill, and learn from mistakes without the pressure of a deadline.
During these first tentative steps you'll learn a lot about distributed computing. You'll have to deal with cloud SLA, set up SLAs for your own services, implement monitoring and alerts, define channels for cross-team communication, and decide on a deployment strategy.
Pick something easy to start with, like edge services that have little overlap with the rest of the monolith. You could, for instance, build an authentication microservice and route login requests as a first step.
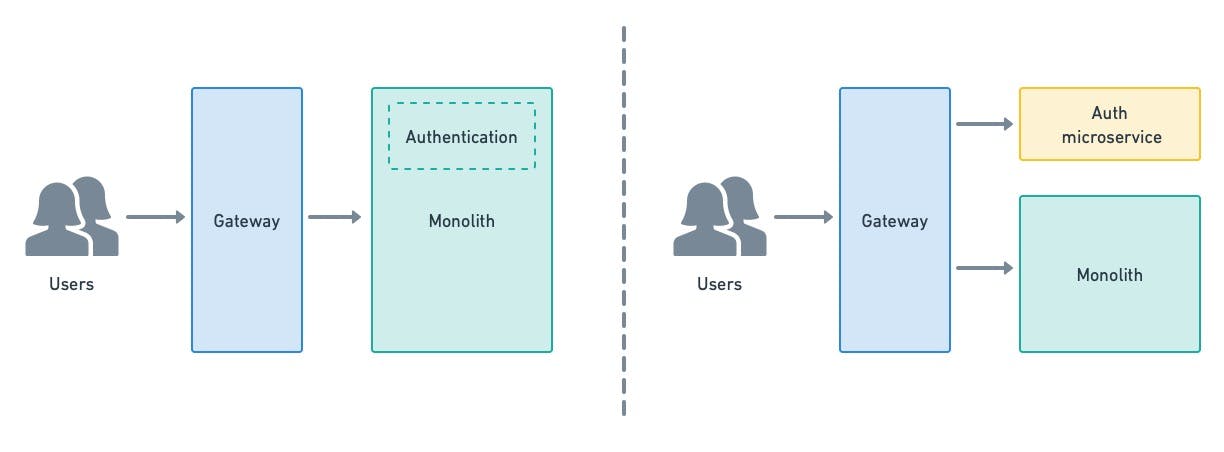
Caption: pick something easy to start, like a simple edge service.
Use feature flags
Feature flags are a software technique for changing the functionality of a system without having to re-deploy it. You can use feature flags to turn on and off portions of the monolith as they are migrated, experiment with alternative configurations, or run A/B testing.
An typical workflow for a feature-flag-enabled migration is:
- Identify a piece of the monolith’s functionality to migrate to a microservice.
- Wrap the functionality with a feature flag. Re-deploy the monolith.
- Build and deploy the microservice.
- Test the microservice.
- Once satisfied, disable the feature on the monolith by switching the feature off.
- Repeat until the migration is complete.
Because feature flags allow us to deploy inactive code to production and toggle it at any time, we can decouple feature releases from actual deployment. This gives developers an enormous degree of flexibility and control.
Modularize the monolith
If your monolith is a tangle of code, you may very well end up with a tangle of distributed code once the migration is done. Like tidying up a house before a total renovation, modularizing the monolith is a necessary preparation step.
The modular monolith is a software development pattern consisting of vertically-stacked modules which are independent and interchangeable. The opposite of a modular monolith is the classic N-tier, or layered, monolith.
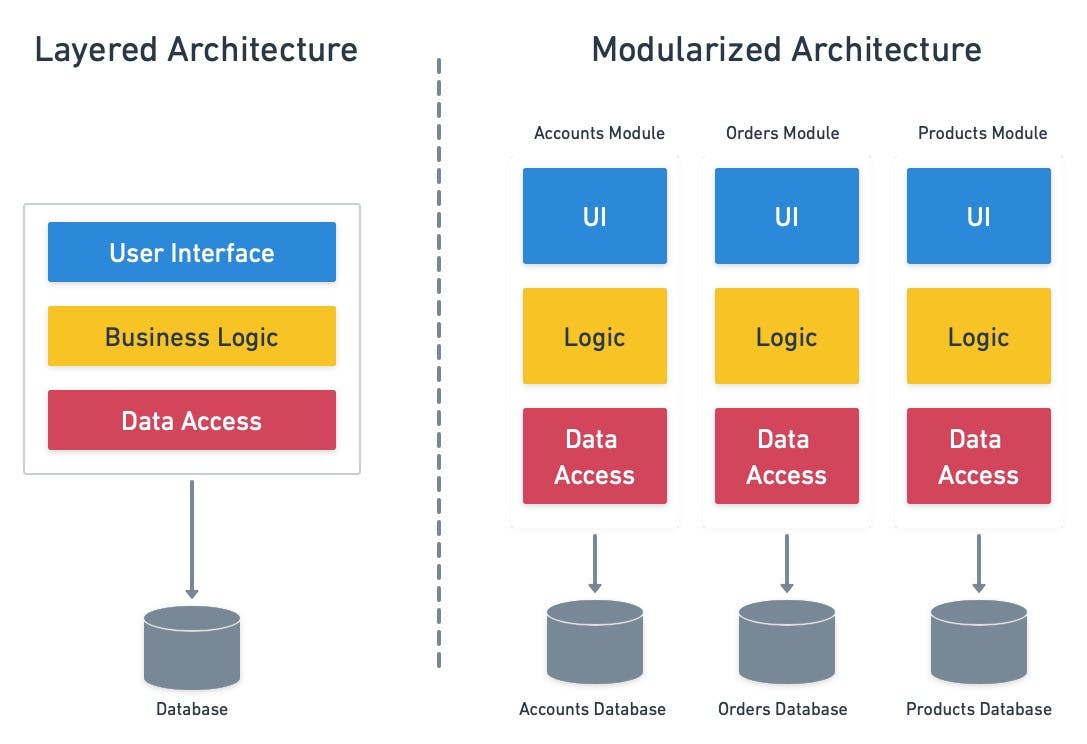
Caption: layered vs. modular monolith architectures.
Layered monoliths are hard to disentangle – code tends to have too many dependencies (sometimes circular), making changes difficult to implement.
A modular monolith is the next best thing to microservices and a stepping stone towards them. The rule is that modules can only communicate over public APIs and everything is private by default. As a result, the code is less intertwined, relationships are easy to identify, and dependencies are clear-cut.
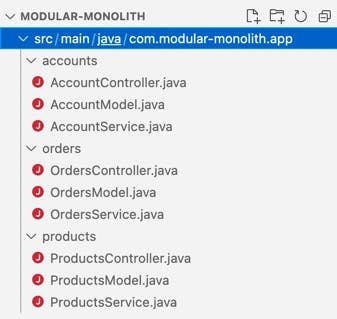
Caption: this Java monolith has been split into independent modules.
Two patterns can help you refactor a monolith: the Strangler Fig and the Anticorruption Layer.
Strangler fig pattern
In the Strangler Fig pattern, we refactor the monolith from the edge to the center. We chew at the edges, progressively rewriting isolated functionality until the monolith is entirely redone.
Calls between modules are routed through the "strangler façade," which emulates and interprets the legacy code's inputs and outputs. Bit by bit, modules are created and slowly replace the old monolith.
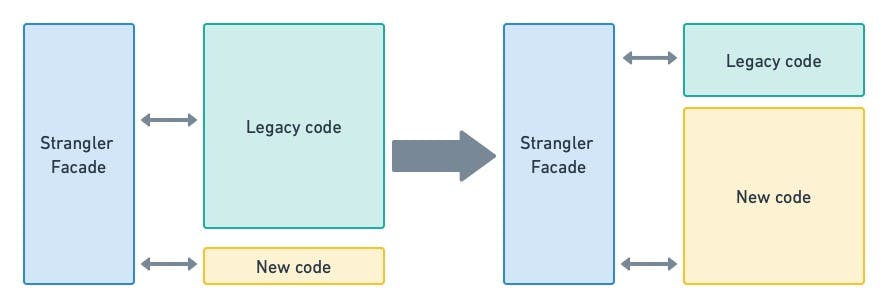
Caption: the monolith is modularized one piece at a time. Eventually, the old monolith is gone and is replaced by a new one.
Anticorruption layer pattern
You will find that, in some cases, changes in one module propagate into others as you refactor the monolith. To combat this, you can create a translation layer between rapidly-changing modules. This anticorruption layer prevents changes in one module from impacting the rest.
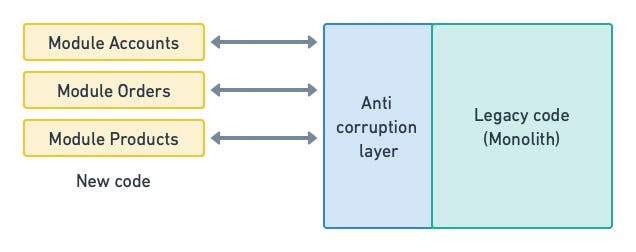
Caption: the anticorruption layer prevents changes from propagating by translating calls between modules and the monolith.
Decoupling the data
The superpower microservices give you is the ability to deploy any microservice at any time with little or no coordination with other microservices. This is why data coupling must be avoided at all costs, as it creates dependencies between services. Each microservice must have a private and independent database.
It can be shocking to realize that you have to denormalize the monolith’s shared database into (often redundant) smaller databases. But data locality is what will ultimately let microservices work autonomously.
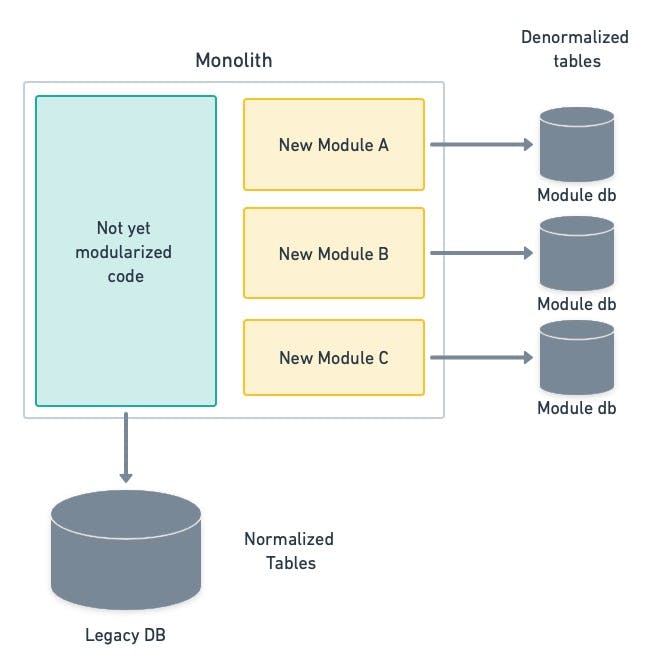 Caption: decoupling data into separate and independent databases.
Caption: decoupling data into separate and independent databases.
After decoupling, you’ll have to install mechanisms to keep the old and new data in sync while the transition is in progress. You can, for example, set up a data-mirroring service or change the code, so transactions are written to both sets of databases.
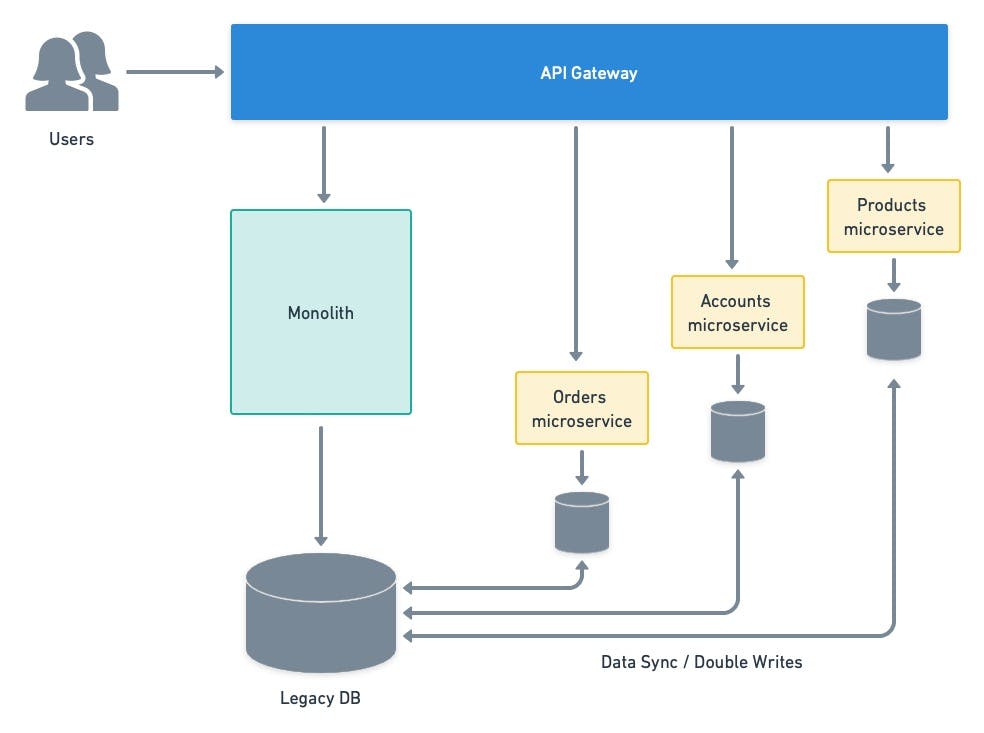
Caption: use data duplication to keep tables in sync during development.
Add observability
The new system must be faster, more performant, and more scalable than the old one. Otherwise, why bother with microservices?
You need a baseline to compare the old with the new. Before starting the migration, ensure you have good metrics and logs available. It may be a good idea to install some centralized logging and monitoring service, since it's a key component for the observability of any microservice application.
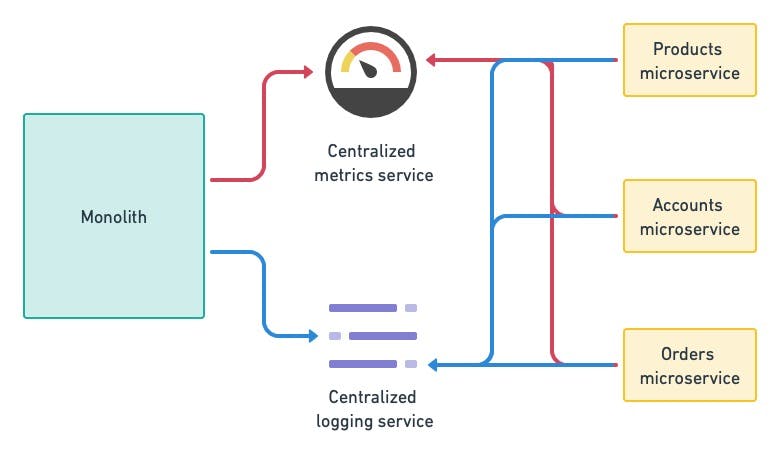
Caption: Metrics are used to compare the performance
Conclusion
The journey to microservices is never an easy one. But I hope that with these tips, you can save some time and frustration.
Remember to iterate in small increments, leverage CI/CD to guarantee that the monolith is being tested for regressions, and keep everything in one repository so you can always rewind if something goes wrong.
Happy coding, and thanks for reading!