Database Management With CI/CD
If you’re still doing manual migrations on the database you’re doing it wrong.


I remember my first day as a junior dev. It’s still fresh in my mind like it was yesterday. I was terribly nervous and had no idea what I was doing. My anxiety must have been evident because a kind soul decided to take me under their wing. That day I learned how to write SQL in my PHP code to do interesting things with the database.
Before I could start, though, I had to ask the database administrator (DBA) to create a few tables. I quickly realized that the DBA was the go-to person if you wanted to get anything done. Need a new column? Call the DBA. A stored procedure has to be edited? It was a job for the DBA. I looked up to him. He was such a superstar that I went on to be a DBA myself for a spell later in my career.
Of course, now I realize that depending on someone for everything inevitably causes bottlenecks. It’s reckless, stressful, and, worst of all, a waste of the DBA’s talents.
Managing data with CI/CD
Automating data management with CI/CD allows us to stay agile by keeping the database schema updated as part of the delivery or deployment process. We can initialize test databases under different conditions and migrate the schema as needed, ensuring testing is done on the correct database version. We can upgrade and downgrade simultaneously when we deploy our applications. Automated data management allows us to keep track of every change in the database, which helps debug production problems.
Using CI/CD to manage data is the only way to properly perform continuous deployment.
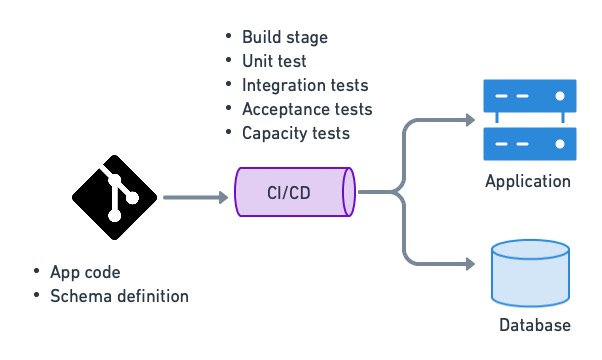 CI/CD is used to deploy applications and update database structures.
CI/CD is used to deploy applications and update database structures.
The role of the DBA
What’s the role of the DBA when data management is automated? Are they irrelevant? On the contrary, relieved from menial chores, they are now free to focus on value-adding work that’s far more engaging, like:
- Monitoring and optimizing database engine performance.
- Advising schema design.
- Planning data normalization.
- Peer reviewing database changes and migration scripts while considering their impact on database operations.
- Deciding the best moment to apply migrations.
- Ensuring the recovery strategy works according to SLA needs.
- Writing or improving migration scripts.
Techniques for data management with CI/CD
What makes database management complicated is that we must preserve the data while making changes to the schema. We can't replace the database with each release as we do with the application.
This problem is even more challenging when we consider that the database must remain online during migrations, and nothing can be lost in the event of a rollback.
So, let’s explore a few techniques to help us make migrations safe.
Commit database scripts to version control
Generally, there are two kinds of database scripts: data-definition language (DDL) and data-manipulation language (DML). DDL creates and modifies database structures such as tables, indexes, triggers, stored procedures, permissions, or views. DML is used to manipulate the actual data in the tables.
Like all code, both kinds of scripts should be kept in version control. Keeping changes in version control lets us reconstruct the entire history of the database schema. This makes changes visible to the team, so they can be peer-reviewed. Database scripts include:
- Scripts to roll the database version forward and backward between different versions.
- Scripts to generate custom datasets for acceptance and capacity testing.
- Database schema definitions used to initialize a new database.
- Any other scripts that change or update data.
Use database migration tools
There are many tools for writing and maintaining migration scripts. Some frameworks, like Rails, Laravel, and Django, come with them built-in. But if that’s not the case for your stack, there are generic tools like Flyway, DBDeploy, and SQLCompare to do the job.
The aim of all these tools is to maintain an uninterrupted set of delta scripts that upgrade and downgrade the database schema as needed. These tools can determine which updates are needed by examining the existing schema and running the update scripts in the correct sequence. They are a much safer alternative than writing scripts by hand.
For instance, to go from version 66 to 70, the migration tool would execute scripts numbered 66, 67, 68, 69, and 70. The same can be done the other way around to roll the database backward.
| Version | Upgrade script | Rollback script | Schema DDL |
| ... | |||
| 66 | delta-66.sql | undo-66.sql | schema-66.sql |
| 67 | delta-67.sql | undo-67.sql | schema-67.sql |
| 68 | delta-68.sql | undo-68.sql | schema-68.sql |
| 69 | delta-69.sql | undo-69.sql | schema-69.sql |
| 70 | delta-70.sql | undo-70.sql | schema-70.sql |
| ... |
Automated migrations cover 99% of your data management needs. Are there cases where management must take place outside CI/CD? Yes, but they are typically one-shot or situationally specific changes, where massive amounts of data must be moved as part of an extensive engineering effort. An excellent example of this is Stripe’s bajillion record migration.
Keep changes small
In software development, we go faster when we can walk in safe, small steps. This is a policy that also applies to data management. Making broad, sweeping changes all at once can lead to unexpected results, like losing data or locking up a table. It’s best to parcel out changes in pieces and apply them over time.
Decouple deployment from data migrations
Application deployment and data migration have very different characteristics. While a deployment usually takes seconds and can occur several times a day, database migrations are more infrequent and executed outside peak hours.
We must separate data migration from application deployment since they need different approaches. Decoupling makes both tasks easier and safer.
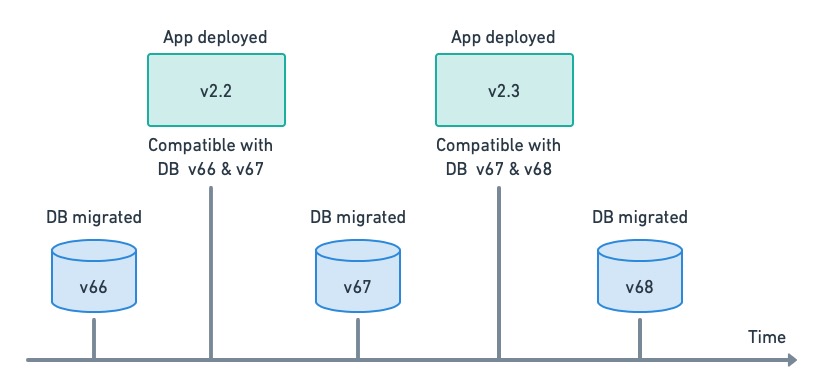 Decoupling app deployment and DB migrations. Each release has a range of compatible DB versions.
Decoupling app deployment and DB migrations. Each release has a range of compatible DB versions.
Decoupling can only work if the application has some leeway regarding database compatibility, i.e. the application’s design should strive to make it as backward-compatible as possible.
Set up continuous deployment and migration pipelines
Uncoupling migration from deployment allows us to split the continuous delivery pipelines in two: one for the migration of the database and one for the deployment of the application. This gives us the benefit of continuously deploying the application while controlling when migrations run. On Semaphore, we can use change-based workflows to automatically trigger the relevant pipeline.
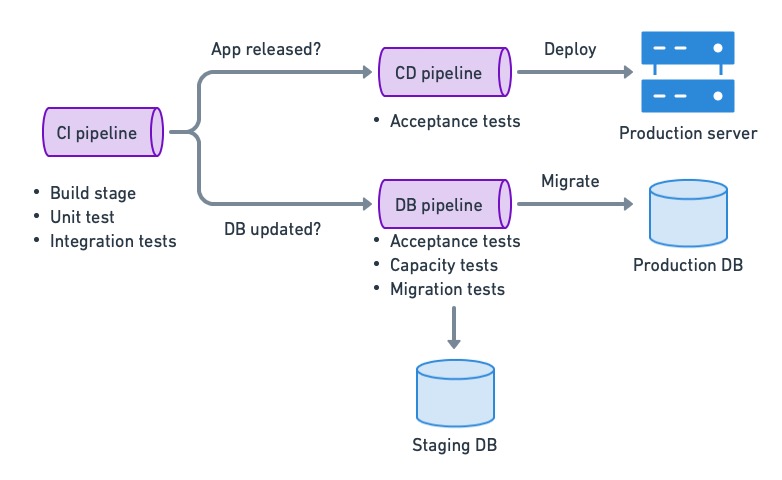 Continuous deployment for databases using the decoupled strategy.
Continuous deployment for databases using the decoupled strategy.
Make migrations additive
Additive database changes create new tables, columns, or stored procedures instead of renaming, overwriting, or deleting them. These kinds of changes are safer because they can be rolled back with the guarantee that data is not lost.
For example, let’s say we have the following table in our production database.
CREATE TABLE pokedex (
id BIGINT GENERATED BY DEFAULT AS IDENTITY (START WITH 1) PRIMARY KEY,
name VARCHAR(255)
category VARCHAR(255)
);
Adding a new column would be an additive change:
ALTER TABLE pokedex ADD COLUMN height float;
Rolling back the change is simply a matter of deleting the new column:
ALTER TABLE pokedex DROP COLUMN height;
We can’t always make additive changes, however. When we need to change or delete data, we can keep data integrity by temporarily saving the original data. For example, changing a column type may truncate the original data. We can make the change safer by saving the old data in a temporary column.
ALTER TABLE pokedex RENAME COLUMN description to description_legacy;
ALTER TABLE pokedex ADD COLUMN description JSON;
UPDATE pokedex SET description = CAST(description_legacy AS JSON);
Having taken that precaution, we can rollback without risk:
ALTER TABLE pokedex DROP COLUMN description;
ALTER TABLE pokedex RENAME COLUMN description_legacy to description;
Rollback with CI/CD
Be it to downgrade the application or because a migration failed, there are some situations in which we have to undo database changes, effectively rolling it back to a past schema version. This is not a big problem as long as we have the rollback script and have kept changes non-destructive.
As with any migration, the rollback should also be scripted and automated (I’ve seen plenty of cases where a manual rollback made things worse). On Semaphore, this can be achieved with a rollback pipeline and promotion conditions.
Don’t do a full backup unless it’s fast
Despite all precautions, things can go wrong, and a failed upgrade can corrupt the database. There must always be some backup mechanism to restore the database to a working state.
The question is: should we make a backup before every migration? The answer depends on the size of the database. If the database backup takes a few seconds, we can do it. However, most databases are too big and take too long to back up to be practical. We must then rely on whichever restore strategy we have available, like daily or weekly full dumps coupled with transaction point-in-time recovery.
As a sidebar, we should test our recovery strategy periodically. It’s easy to grow confident that we have valid backups, but we can’t be sure until we try them. Don’t wait for a disaster to try restoring the database — have some disaster recovery plan in place and play it out from time to time.
Consider blue-green deployments
⚠️ Blue-green deployments are a more sophisticated technique that requires a good deal of familiarity with how database engines work. So, I recommend using it with care and once you have confidence in managing data in the CI/CD process.
Blue-green deployments is a strategy that allows us to instantly switch between versions. The gist of blue-green deployments is to have two separate environments, dubbed blue and green. One is active (has users), while the other is upgraded. Users are switched back and forth as needed.
We can put blue-green’s instant rollback feature to good use if we have separate databases. Before deployment, the inactive system (green in the figure below) receives a current database restore from blue, and it’s kept in sync with a mirroring mechanism. Then, it is migrated to the next version.
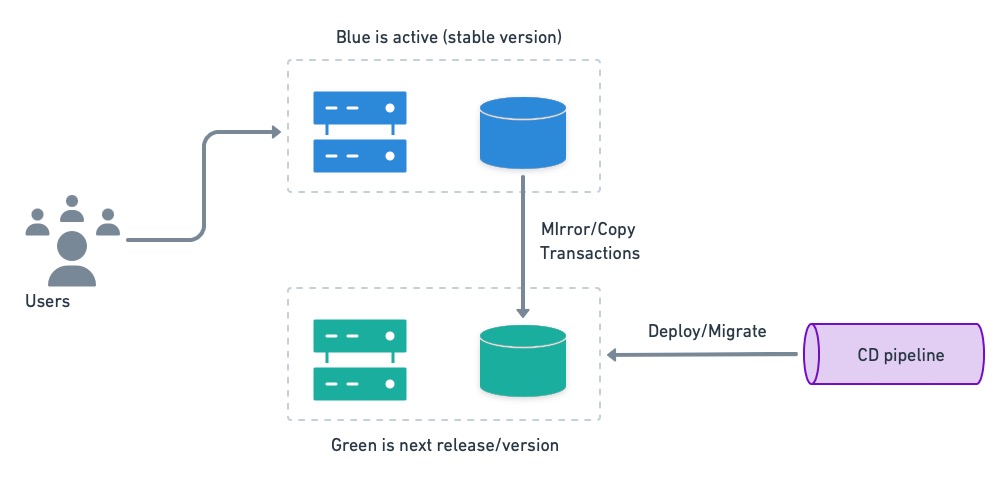
Once the inactive system is upgraded and tested, users are switched over.
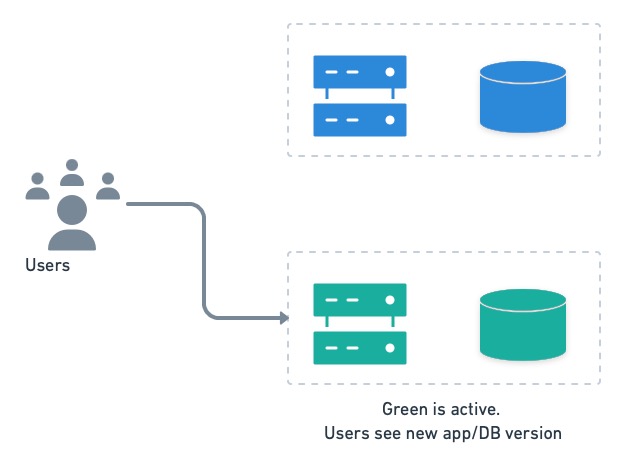 Users are switched to the next version running on green.
Users are switched to the next version running on green.
In case of trouble, users can be switched back to the old version in an instant. The only catch with this setup is that transactions executed by the users on the green side must be replayed on blue after the rollback.
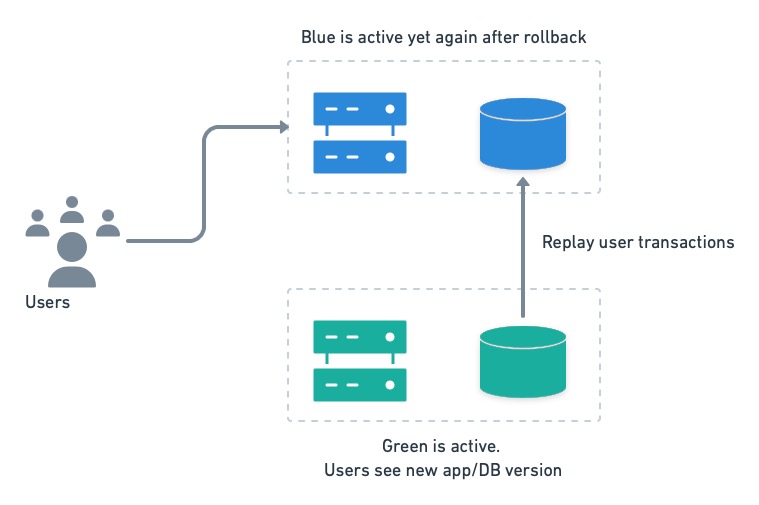 On rollback, we must rerun green’s transactions on blue to avoid losing data.
On rollback, we must rerun green’s transactions on blue to avoid losing data.
Testing techniques
Because a migration can destroy data or cause an outage, we want to be extra careful and test it thoroughly before going to production. Fortunately, there are quite a few testing techniques available to help us.
Unit and integration tests
Unit tests, as a general rule, should not depend on or access a database if possible. The objective of a unit test is to check the behavior of a function or method. We can usually get away with stubs or mocks for this. When that’s not possible or is too inconvenient, we can use in-memory databases for the job.
On the other hand, actual databases are commonly seen in integration testing. These can be spun up on-demand for the test, loaded with empty tables or a specially-crafted dataset, and shut down after testing.
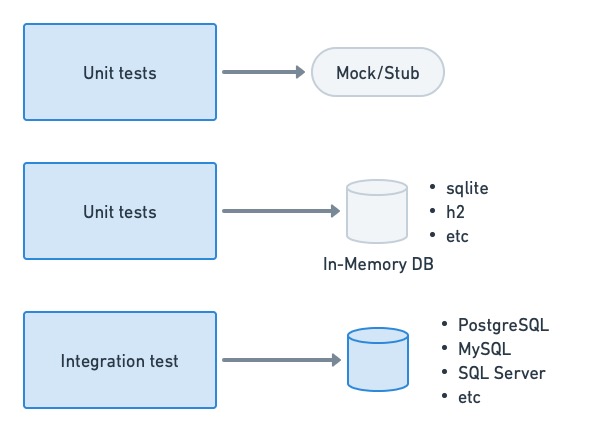 Unit tests should not depend too heavily on database access. For integration tests, we tend to use a real database engine.
Unit tests should not depend too heavily on database access. For integration tests, we tend to use a real database engine.
Acceptance and end-to-end tests
We need an environment that closely resembles production for acceptance testing. While it’s tempting to use anonymized, production backups in the test database, they tend to be too big and unwieldy to be useful. Instead, we can use crafted datasets or, even better, create the empty schema and use the application’s internal API to populate it with test data.
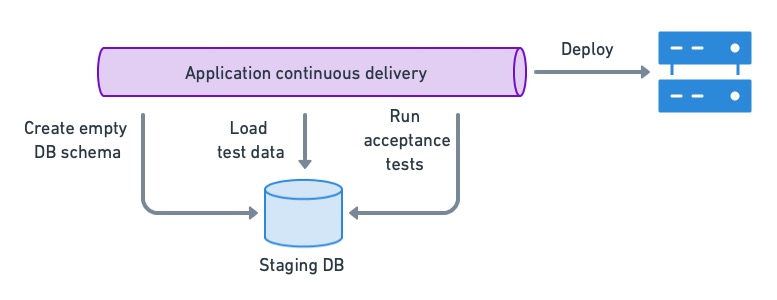 To ensure that the app is compatible with the current DB version, we load a test dataset in a staging DB and run acceptance tests. If they pass, we can deploy the application.
To ensure that the app is compatible with the current DB version, we load a test dataset in a staging DB and run acceptance tests. If they pass, we can deploy the application.
Compatibility and migration tests
We must perform regression testing if we’re aiming for the application to be backward and forward compatible with multiple database versions. This can be done by running acceptance tests on the database schema before and after the migration.
On an uncoupled setup like the one described earlier, the application’s continuous deployment pipeline would perform acceptance testing on the current schema version. So, we only need to acceptance test the next database version when a migration takes place:
- Load the test database with the current production schema.
- Run the migration.
- Run acceptance tests.
This method has the added benefit of detecting problems in the migration script itself, as many things can go wrong, like new constraints failing due to existing data, name collisions, or tables getting locked up for too long.
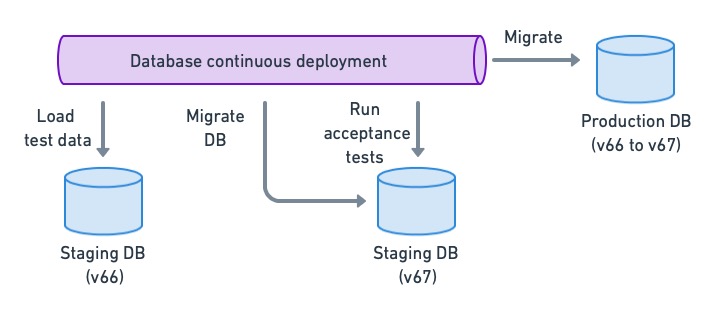 Running acceptance tests on the migrated DB schema allows us to detect regressions and find possible migration conflicts.
Running acceptance tests on the migrated DB schema allows us to detect regressions and find possible migration conflicts.
Closing thoughts
Database scripts should be treated the same as the rest of the code — the same principles apply. Ensure your DBAs have access to the code repository so they can help setup, revise & peer-review the data management scripts. These scripts should be versioned and subjected to the same level of scrutiny as the code.
The effort invested in setting up automated data management with CI/CD will be repaid many times over in speed, stability, and productivity. Developers can work unencumbered while DBAs do what they’re best at: keeping the database clean and well-oiled.
Thanks for reading!